[번역] microgpt - 200줄의 순수 파이썬으로 GPT를 학습하고 추론하기
이 글은 Andrej Karpathy의 microgpt 포스트를 한국어로 번역한 것입니다.
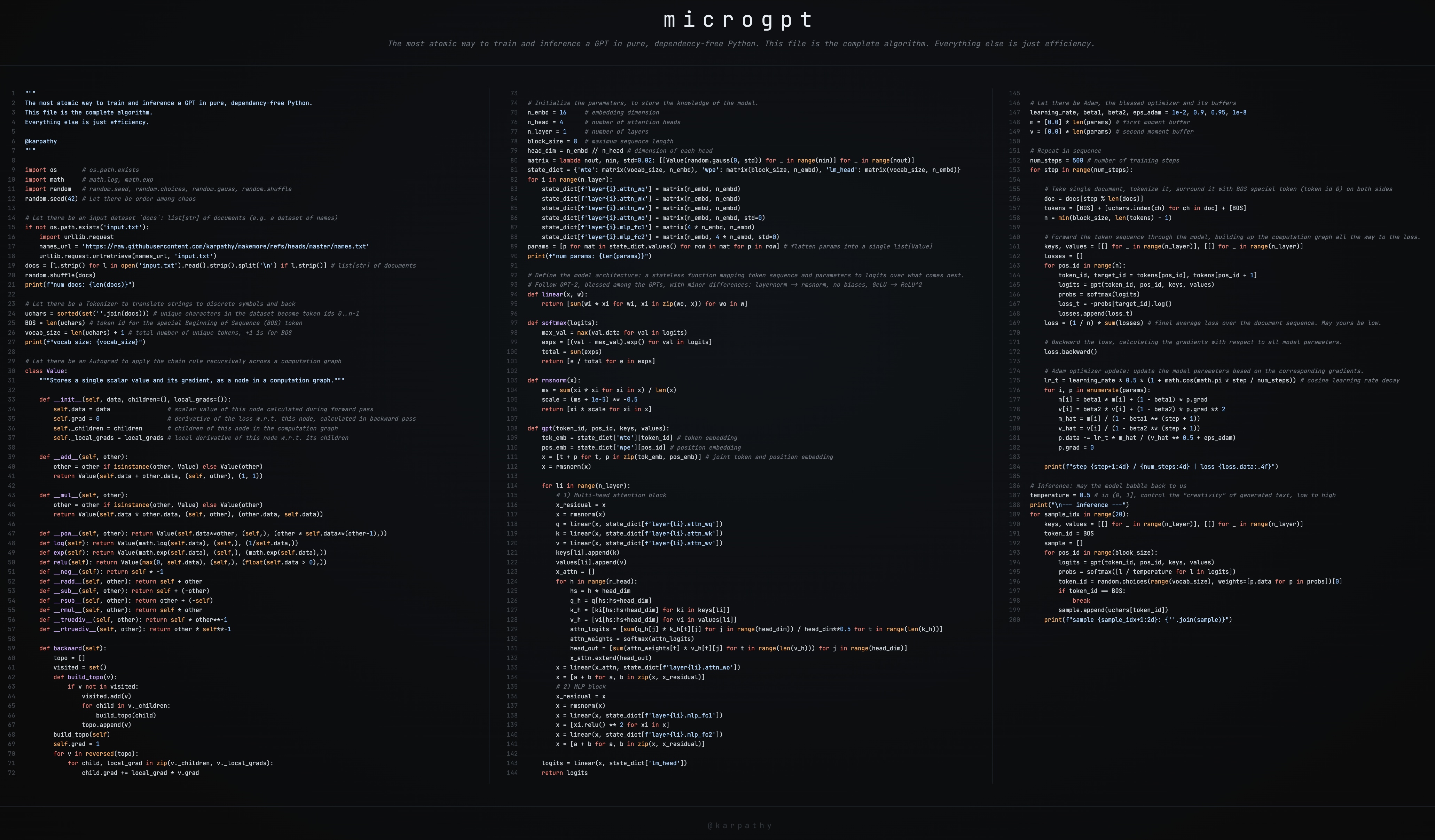
이 글은 제 새로운 아트 프로젝트 microgpt에 대한 간단한 가이드입니다. 의존성 없는 순수 Python 200줄짜리 단일 파일로 GPT를 학습하고 추론합니다. 이 파일에는 필요한 모든 알고리즘적 내용이 담겨 있습니다: 문서 데이터셋, 토크나이저, 자동 미분 엔진, GPT-2 스타일의 신경망 아키텍처, Adam 옵티마이저, 학습 루프, 추론 루프. 나머지는 전부 효율성의 문제입니다. 이것 이상으로 단순화할 수 없습니다. 이 스크립트는 여러 프로젝트(micrograd, makemore, nanogpt 등)와 LLM을 핵심만 남기려는 10년간의 집착의 결정체이며, 저는 이것이 아름답다고 생각합니다 🥹. 심지어 3개의 컬럼으로 완벽하게 나뉘기까지 합니다:
코드를 찾을 수 있는 곳:
- 전체 소스 코드가 담긴 GitHub gist: microgpt.py
- 웹 페이지에서도 볼 수 있습니다: https://karpathy.ai/microgpt.html
- Google Colab 노트북으로도 제공됩니다
다음은 관심 있는 독자를 위해 코드를 단계별로 안내하는 가이드입니다.
데이터셋
대규모 언어 모델의 연료는 텍스트 데이터 스트림이며, 선택적으로 여러 문서로 구분됩니다. 프로덕션급 애플리케이션에서 각 문서는 인터넷 웹 페이지가 되겠지만, microgpt에서는 32,000개의 이름으로 구성된 더 간단한 예제를 사용합니다:
1
2
3
4
5
6
7
8
# 입력 데이터셋 `docs`: list[str] 형태의 문서들 (예: 이름 데이터셋)
if not os.path.exists('input.txt'):
import urllib.request
names_url = 'https://raw.githubusercontent.com/karpathy/makemore/refs/heads/master/names.txt'
urllib.request.urlretrieve(names_url, 'input.txt')
docs = [l.strip() for l in open('input.txt').read().strip().split('\n') if l.strip()] # list[str] 문서들
random.shuffle(docs)
print(f"num docs: {len(docs)}")
데이터셋은 이렇게 생겼습니다. 각 이름이 하나의 문서입니다:
1
2
3
4
5
6
7
8
9
10
emma
olivia
ava
isabella
sophia
charlotte
mia
amelia
harper
... (~32,000개의 이름이 이어집니다)
모델의 목표는 데이터의 패턴을 학습하고, 동일한 통계적 패턴을 공유하는 새로운 유사한 문서를 생성하는 것입니다. 미리 보자면, 스크립트의 끝에서 우리 모델은 새로운, 그럴듯한 이름들을 생성(“환각”)합니다:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
sample 1: kamon
sample 2: ann
sample 3: karai
sample 4: jaire
sample 5: vialan
sample 6: karia
sample 7: yeran
sample 8: anna
sample 9: areli
sample 10: kaina
sample 11: konna
sample 12: keylen
sample 13: liole
sample 14: alerin
sample 15: earan
sample 16: lenne
sample 17: kana
sample 18: lara
sample 19: alela
sample 20: anton
별것 아닌 것처럼 보이지만, ChatGPT 같은 모델의 관점에서 보면 여러분과의 대화도 그저 좀 특이하게 생긴 “문서”일 뿐입니다. 프롬프트로 문서를 시작하면, 모델의 응답은 모델 입장에서 그저 통계적 문서 완성에 불과합니다.
토크나이저
내부적으로 신경망은 문자가 아닌 숫자로 작동하므로, 텍스트를 정수 토큰 id 시퀀스로 변환하고 다시 되돌리는 방법이 필요합니다. tiktoken(GPT-4에서 사용)과 같은 프로덕션 토크나이저는 효율성을 위해 문자 청크 단위로 작동하지만, 가장 단순한 토크나이저는 데이터셋의 각 고유 문자에 하나의 정수를 할당합니다:
1
2
3
4
5
# 문자열을 이산 심볼로 변환하고 되돌리는 토크나이저
uchars = sorted(set(''.join(docs))) # 데이터셋의 고유 문자들이 토큰 id 0..n-1이 됨
BOS = len(uchars) # 특수 시퀀스 시작(BOS) 토큰의 토큰 id
vocab_size = len(uchars) + 1 # 고유 토큰의 총 수, +1은 BOS용
print(f"vocab size: {vocab_size}")
위 코드에서 데이터셋 전체의 고유 문자들(소문자 a-z)을 수집하고 정렬한 뒤, 각 문자가 인덱스로 id를 받습니다. 정수 값 자체에는 아무런 의미가 없다는 점에 주목하세요. 각 토큰은 그저 별개의 이산 심볼입니다. 0, 1, 2 대신 서로 다른 이모지여도 상관없습니다. 추가로 BOS(Beginning of Sequence)라는 특수 토큰을 하나 더 만듭니다. 이것은 구분자 역할을 하여 모델에게 “새 문서가 여기서 시작/끝납니다”를 알려줍니다. 나중에 학습 시 각 문서는 양쪽에 BOS로 감싸집니다: [BOS, e, m, m, a, BOS]. 모델은 BOS가 새 이름을 시작하고, 또 다른 BOS가 끝낸다는 것을 학습합니다. 따라서 최종 어휘는 27개입니다(소문자 a-z 26개 + BOS 토큰 1개).
자동 미분 (Autograd)
신경망을 학습하려면 그래디언트가 필요합니다: 모델의 각 파라미터에 대해 “이 숫자를 조금 올리면 손실이 올라가나 내려가나, 그리고 얼마나?”를 알아야 합니다. 계산 그래프는 많은 입력(모델 파라미터와 입력 토큰)을 가지지만 하나의 스칼라 출력인 손실(loss)로 수렴합니다. 역전파는 그 단일 출력에서 시작하여 그래프를 거꾸로 따라가며, 모든 입력에 대한 손실의 그래디언트를 계산합니다. 이것은 미적분의 연쇄 법칙(chain rule)에 의존합니다. 프로덕션에서는 PyTorch 같은 라이브러리가 이를 자동으로 처리합니다. 여기서는 Value라는 단일 클래스로 처음부터 구현합니다:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
class Value:
__slots__ = ('data', 'grad', '_children', '_local_grads')
def __init__(self, data, children=(), local_grads=()):
self.data = data # 순전파에서 계산된 이 노드의 스칼라 값
self.grad = 0 # 이 노드에 대한 손실의 도함수, 역전파에서 계산
self._children = children # 계산 그래프에서 이 노드의 자식들
self._local_grads = local_grads # 자식에 대한 이 노드의 국소 도함수
def __add__(self, other):
other = other if isinstance(other, Value) else Value(other)
return Value(self.data + other.data, (self, other), (1, 1))
def __mul__(self, other):
other = other if isinstance(other, Value) else Value(other)
return Value(self.data * other.data, (self, other), (other.data, self.data))
def __pow__(self, other): return Value(self.data**other, (self,), (other * self.data**(other-1),))
def log(self): return Value(math.log(self.data), (self,), (1/self.data,))
def exp(self): return Value(math.exp(self.data), (self,), (math.exp(self.data),))
def relu(self): return Value(max(0, self.data), (self,), (float(self.data > 0),))
def __neg__(self): return self * -1
def __radd__(self, other): return self + other
def __sub__(self, other): return self + (-other)
def __rsub__(self, other): return other + (-self)
def __rmul__(self, other): return self * other
def __truediv__(self, other): return self * other**-1
def __rtruediv__(self, other): return other * self**-1
def backward(self):
topo = []
visited = set()
def build_topo(v):
if v not in visited:
visited.add(v)
for child in v._children:
build_topo(child)
topo.append(v)
build_topo(self)
self.grad = 1
for v in reversed(topo):
for child, local_grad in zip(v._children, v._local_grads):
child.grad += local_grad * v.grad
이것이 수학적, 알고리즘적으로 가장 집약적인 부분이며 이에 대한 2.5시간짜리 영상이 있습니다: micrograd 영상. 간단히 말해, Value는 하나의 스칼라 숫자(.data)를 감싸고 그것이 어떻게 계산되었는지 추적합니다. 각 연산을 작은 레고 블록으로 생각하세요: 몇 가지 입력을 받아 출력을 생성하고(순전파), 각 입력에 대한 출력의 변화율(국소 그래디언트)을 알고 있습니다. 이것이 자동 미분이 각 블록에서 필요로 하는 전부입니다. 나머지는 전부 연쇄 법칙, 즉 블록들을 연결하는 것입니다.
Value 객체로 수학 연산(더하기, 곱하기 등)을 할 때마다, 결과는 자신의 입력(_children)과 해당 연산의 국소 도함수(_local_grads)를 기억하는 새로운 Value입니다. 예를 들어 __mul__은 \(\frac{\partial(a \cdot b)}{\partial a} = b\) 와 \(\frac{\partial(a \cdot b)}{\partial b} = a\) 를 기록합니다. 전체 레고 블록 목록:
| 연산 | 순전파 | 국소 그래디언트 |
|---|---|---|
a + b | \(a + b\) | \(\frac{\partial}{\partial a} = 1, \quad \frac{\partial}{\partial b} = 1\) |
a * b | \(a \cdot b\) | \(\frac{\partial}{\partial a} = b, \quad \frac{\partial}{\partial b} = a\) |
a ** n | \(a^n\) | \(\frac{\partial}{\partial a} = n \cdot a^{n-1}\) |
log(a) | \(\ln(a)\) | \(\frac{\partial}{\partial a} = \frac{1}{a}\) |
exp(a) | \(e^a\) | \(\frac{\partial}{\partial a} = e^a\) |
relu(a) | \(\max(0, a)\) | \(\frac{\partial}{\partial a} = \mathbf{1}_{a > 0}\) |
backward() 메서드는 이 그래프를 역 위상 정렬 순서로 순회합니다(손실에서 시작하여 파라미터에서 끝남). 각 단계에서 연쇄 법칙을 적용합니다. 손실이 \(L\)이고 노드 \(v\)가 국소 그래디언트 \(\frac{\partial v}{\partial c}\)를 가진 자식 \(c\)를 갖는다면:
미적분에 익숙하지 않다면 무서워 보일 수 있지만, 사실 직관적으로 두 수를 곱하는 것일 뿐입니다. 이렇게 보면 됩니다: “자동차가 자전거보다 2배 빠르고, 자전거가 걷는 사람보다 4배 빠르면, 자동차는 사람보다 2 x 4 = 8배 빠르다.” 연쇄 법칙도 같은 아이디어입니다: 경로를 따라 변화율을 곱합니다.
손실 노드에서 self.grad = 1을 설정하여 시작합니다. \(\frac{\partial L}{\partial L} = 1\)이기 때문입니다: 손실의 자기 자신에 대한 변화율은 당연히 1입니다. 거기서부터 연쇄 법칙이 파라미터까지의 모든 경로를 따라 국소 그래디언트를 곱합니다.
+=(대입이 아닌 누적)에 주목하세요. 값이 그래프의 여러 곳에서 사용될 때(즉 그래프가 분기할 때), 그래디언트는 각 분기를 따라 독립적으로 흐르며 합산되어야 합니다. 이것은 다변수 연쇄 법칙의 결과입니다.
backward()가 완료되면, 그래프의 모든 Value는 \(\frac{\partial L}{\partial v}\)를 담고 있는 .grad를 갖게 되며, 이는 해당 값을 살짝 변경했을 때 최종 손실이 어떻게 변하는지를 알려줍니다.
구체적인 예시입니다. a가 두 번 사용되므로(그래프가 분기) 그래디언트는 양쪽 경로의 합입니다:
1
2
3
4
5
6
7
a = Value(2.0)
b = Value(3.0)
c = a * b # c = 6.0
L = c + a # L = 8.0
L.backward()
print(a.grad) # 4.0 (dL/da = b + 1 = 3 + 1, 양쪽 경로를 통해)
print(b.grad) # 2.0 (dL/db = a = 2)
이것은 PyTorch의 .backward()가 주는 것과 정확히 같습니다:
1
2
3
4
5
6
7
8
import torch
a = torch.tensor(2.0, requires_grad=True)
b = torch.tensor(3.0, requires_grad=True)
c = a * b
L = c + a
L.backward()
print(a.grad) # tensor(4.)
print(b.grad) # tensor(2.)
PyTorch의 loss.backward()가 실행하는 것과 동일한 알고리즘이며, 텐서(스칼라 배열) 대신 스칼라에서 작동할 뿐입니다 - 알고리즘적으로 동일하고, 훨씬 작고 단순하지만, 물론 훨씬 덜 효율적입니다.
파라미터
파라미터는 모델의 지식입니다. 무작위로 시작하여 학습 중 반복적으로 최적화되는 부동소수점 숫자들의 큰 컬렉션입니다(자동 미분을 위해 Value로 감싸져 있음). 각 파라미터의 정확한 역할은 아래에서 모델 아키텍처를 정의하면 더 이해가 되겠지만, 지금은 초기화만 하면 됩니다:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
n_embd = 16 # 임베딩 차원
n_head = 4 # 어텐션 헤드 수
n_layer = 1 # 레이어 수
block_size = 16 # 최대 시퀀스 길이
head_dim = n_embd // n_head # 각 헤드의 차원
matrix = lambda nout, nin, std=0.08: [[Value(random.gauss(0, std)) for _ in range(nin)] for _ in range(nout)]
state_dict = {'wte': matrix(vocab_size, n_embd), 'wpe': matrix(block_size, n_embd), 'lm_head': matrix(vocab_size, n_embd)}
for i in range(n_layer):
state_dict[f'layer{i}.attn_wq'] = matrix(n_embd, n_embd)
state_dict[f'layer{i}.attn_wk'] = matrix(n_embd, n_embd)
state_dict[f'layer{i}.attn_wv'] = matrix(n_embd, n_embd)
state_dict[f'layer{i}.attn_wo'] = matrix(n_embd, n_embd)
state_dict[f'layer{i}.mlp_fc1'] = matrix(4 * n_embd, n_embd)
state_dict[f'layer{i}.mlp_fc2'] = matrix(n_embd, 4 * n_embd)
params = [p for mat in state_dict.values() for row in mat for p in row]
print(f"num params: {len(params)}")
각 파라미터는 가우시안 분포에서 뽑은 작은 난수로 초기화됩니다. state_dict는 이들을 명명된 행렬로 정리합니다(PyTorch 용어를 차용): 임베딩 테이블, 어텐션 가중치, MLP 가중치, 최종 출력 프로젝션. 나중에 옵티마이저가 순회할 수 있도록 모든 파라미터를 단일 리스트 params로 평탄화합니다. 우리의 작은 모델에서 이는 4,192개의 파라미터입니다. GPT-2는 16억 개, 현대 LLM은 수천억 개를 가집니다.
아키텍처
모델 아키텍처는 상태 없는(stateless) 함수입니다: 토큰, 위치, 파라미터, 이전 위치의 캐시된 키/값을 받아서 시퀀스에서 다음에 올 토큰에 대한 로짓(점수)을 반환합니다. GPT-2를 따르되 약간의 단순화를 합니다: LayerNorm 대신 RMSNorm, 바이어스 없음, GeLU 대신 ReLU. 먼저 세 가지 작은 헬퍼 함수입니다:
1
2
def linear(x, w):
return [sum(wi * xi for wi, xi in zip(wo, x)) for wo in w]
linear는 행렬-벡터 곱입니다. 벡터 x와 가중치 행렬 w를 받아 w의 각 행에 대해 내적을 계산합니다. 이것이 신경망의 기본 빌딩 블록입니다: 학습된 선형 변환.
1
2
3
4
5
def softmax(logits):
max_val = max(val.data for val in logits)
exps = [(val - max_val).exp() for val in logits]
total = sum(exps)
return [e / total for e in exps]
softmax는 \(-\infty\)에서 \(+\infty\) 범위의 원시 점수(로짓) 벡터를 확률 분포로 변환합니다: 모든 값이 \([0, 1]\) 범위가 되고 합이 1이 됩니다. 수치 안정성을 위해 먼저 최댓값을 빼줍니다(수학적으로 결과는 변하지 않지만 exp에서 오버플로우를 방지합니다).
1
2
3
4
def rmsnorm(x):
ms = sum(xi * xi for xi in x) / len(x)
scale = (ms + 1e-5) ** -0.5
return [xi * scale for xi in x]
rmsnorm(Root Mean Square Normalization)은 벡터를 단위 RMS를 갖도록 재조정합니다. 이는 네트워크를 통과하면서 활성화가 커지거나 작아지는 것을 방지하여 학습을 안정화합니다. 원래 GPT-2에서 사용된 LayerNorm의 더 단순한 변형입니다.
이제 모델 자체입니다:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
def gpt(token_id, pos_id, keys, values):
tok_emb = state_dict['wte'][token_id] # 토큰 임베딩
pos_emb = state_dict['wpe'][pos_id] # 위치 임베딩
x = [t + p for t, p in zip(tok_emb, pos_emb)] # 토큰과 위치 임베딩 결합
x = rmsnorm(x)
for li in range(n_layer):
# 1) 멀티-헤드 어텐션 블록
x_residual = x
x = rmsnorm(x)
q = linear(x, state_dict[f'layer{li}.attn_wq'])
k = linear(x, state_dict[f'layer{li}.attn_wk'])
v = linear(x, state_dict[f'layer{li}.attn_wv'])
keys[li].append(k)
values[li].append(v)
x_attn = []
for h in range(n_head):
hs = h * head_dim
q_h = q[hs:hs+head_dim]
k_h = [ki[hs:hs+head_dim] for ki in keys[li]]
v_h = [vi[hs:hs+head_dim] for vi in values[li]]
attn_logits = [sum(q_h[j] * k_h[t][j] for j in range(head_dim)) / head_dim**0.5 for t in range(len(k_h))]
attn_weights = softmax(attn_logits)
head_out = [sum(attn_weights[t] * v_h[t][j] for t in range(len(v_h))) for j in range(head_dim)]
x_attn.extend(head_out)
x = linear(x_attn, state_dict[f'layer{li}.attn_wo'])
x = [a + b for a, b in zip(x, x_residual)]
# 2) MLP 블록
x_residual = x
x = rmsnorm(x)
x = linear(x, state_dict[f'layer{li}.mlp_fc1'])
x = [xi.relu() for xi in x]
x = linear(x, state_dict[f'layer{li}.mlp_fc2'])
x = [a + b for a, b in zip(x, x_residual)]
logits = linear(x, state_dict['lm_head'])
return logits
이 함수는 특정 위치(pos_id)에 있는 하나의 토큰(token_id)을 처리하며, KV 캐시라고 알려진 keys와 values의 활성화로 요약된 이전 반복의 컨텍스트를 사용합니다. 단계별로 살펴보겠습니다:
임베딩. 신경망은 5 같은 원시 토큰 id를 직접 처리할 수 없습니다. 벡터(숫자 리스트)만 다룰 수 있습니다. 그래서 가능한 각 토큰에 학습된 벡터를 연결하고 그것을 신경 시그니처로 입력합니다. 토큰 id와 위치 id가 각각의 임베딩 테이블(wte와 wpe)에서 행을 찾습니다. 이 두 벡터를 더하면 토큰이 무엇인지와 시퀀스에서 어디에 있는지를 모두 인코딩하는 표현을 얻습니다.
어텐션 블록. 현재 토큰은 세 가지 벡터로 프로젝션됩니다: 쿼리(Q), 키(K), 값(V). 직관적으로, 쿼리는 “나는 무엇을 찾고 있는가?”, 키는 “나는 무엇을 담고 있는가?”, 값은 “선택되면 무엇을 제공하는가?”라고 말합니다. 예를 들어 이름 “emma”에서 모델이 두 번째 “m”에 있으면서 다음에 무엇이 올지 예측하려 할 때, “최근에 어떤 모음이 나왔지?” 같은 쿼리를 학습할 수 있습니다. 앞의 “e”는 이 쿼리와 잘 맞는 키를 가지므로 높은 어텐션 가중치를 받고, 그 값(모음이라는 정보)이 현재 위치로 흐릅니다. 어텐션 블록은 위치 t의 토큰이 과거 0..t-1의 토큰을 “볼” 수 있는 정확하고 유일한 장소라는 점을 강조할 가치가 있습니다. 어텐션은 토큰 통신 메커니즘입니다.
MLP 블록. MLP는 다층 퍼셉트론(multilayer perceptron)의 약자이며, 2층 피드포워드 네트워크입니다: 임베딩 차원의 4배로 확장하고, ReLU를 적용하고, 다시 축소합니다. 이것은 모델이 각 위치에서 대부분의 “사고”를 하는 곳입니다. 어텐션과 달리 이 계산은 시간 t에 완전히 로컬입니다. 트랜스포머는 통신(어텐션)과 계산(MLP)을 번갈아 배치합니다.
잔차 연결. 어텐션과 MLP 블록 모두 출력을 입력에 다시 더합니다(x = [a + b for ...]). 이를 통해 그래디언트가 네트워크를 직접 통과하여 더 깊은 모델을 학습 가능하게 합니다.
출력. 최종 은닉 상태가 lm_head에 의해 어휘 크기로 프로젝션되어 어휘의 각 토큰에 대해 하나의 로짓을 생성합니다. 우리의 경우 단 27개의 숫자입니다. 로짓이 높을수록 = 모델이 해당 토큰이 다음에 올 가능성이 높다고 생각합니다.
학습 루프
이제 모든 것을 연결합니다. 학습 루프는 반복적으로: (1) 문서를 선택하고, (2) 토큰에 대해 모델을 순전파하고, (3) 손실을 계산하고, (4) 역전파로 그래디언트를 얻고, (5) 파라미터를 업데이트합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
# Adam, 축복받은 옵티마이저와 그 버퍼
learning_rate, beta1, beta2, eps_adam = 0.01, 0.85, 0.99, 1e-8
m = [0.0] * len(params) # 1차 모멘트 버퍼
v = [0.0] * len(params) # 2차 모멘트 버퍼
# 순차적으로 반복
num_steps = 1000 # 학습 스텝 수
for step in range(num_steps):
# 단일 문서를 가져와 토크나이즈하고, 양쪽을 BOS 특수 토큰으로 감쌈
doc = docs[step % len(docs)]
tokens = [BOS] + [uchars.index(ch) for ch in doc] + [BOS]
n = min(block_size, len(tokens) - 1)
# 토큰 시퀀스를 모델에 순전파하여 손실까지의 계산 그래프를 구축
keys, values = [[] for _ in range(n_layer)], [[] for _ in range(n_layer)]
losses = []
for pos_id in range(n):
token_id, target_id = tokens[pos_id], tokens[pos_id + 1]
logits = gpt(token_id, pos_id, keys, values)
probs = softmax(logits)
loss_t = -probs[target_id].log()
losses.append(loss_t)
loss = (1 / n) * sum(losses) # 문서 시퀀스에 대한 최종 평균 손실
# 손실을 역전파하여 모든 모델 파라미터에 대한 그래디언트를 계산
loss.backward()
# Adam 옵티마이저 업데이트: 해당 그래디언트를 기반으로 모델 파라미터를 업데이트
lr_t = learning_rate * (1 - step / num_steps) # 선형 학습률 감소
for i, p in enumerate(params):
m[i] = beta1 * m[i] + (1 - beta1) * p.grad
v[i] = beta2 * v[i] + (1 - beta2) * p.grad ** 2
m_hat = m[i] / (1 - beta1 ** (step + 1))
v_hat = v[i] / (1 - beta2 ** (step + 1))
p.data -= lr_t * m_hat / (v_hat ** 0.5 + eps_adam)
p.grad = 0
print(f"step {step+1:4d} / {num_steps:4d} | loss {loss.data:.4f}")
각 부분을 살펴봅시다:
토크나이제이션. 각 학습 스텝은 하나의 문서를 선택하고 양쪽을 BOS로 감쌉니다: 이름 “emma”는 [BOS, e, m, m, a, BOS]가 됩니다. 모델의 임무는 이전 토큰들이 주어졌을 때 각 다음 토큰을 예측하는 것입니다.
순전파와 손실. 토큰을 한 번에 하나씩 모델에 입력하면서 KV 캐시를 쌓아갑니다. 각 위치에서 모델은 27개의 로짓을 출력하고, softmax로 확률로 변환합니다. 각 위치의 손실은 정답 다음 토큰의 음의 로그 확률입니다: \(-\log p(\text{target})\). 이것을 교차 엔트로피 손실이라고 합니다. 직관적으로 손실은 오예측의 정도를 측정합니다: 모델이 실제로 다음에 오는 것에 얼마나 놀랐는지. 모델이 정답 토큰에 확률 1.0을 부여하면 전혀 놀라지 않고 손실은 0입니다. 확률이 0에 가까우면 모델은 매우 놀라고 손실은 \(+\infty\)로 갑니다.
역전파. loss.backward() 한 번의 호출로 전체 계산 그래프를 통해 역전파가 실행됩니다. 이후 각 파라미터의 .grad가 손실을 줄이기 위해 어떻게 변경해야 하는지를 알려줍니다.
Adam 옵티마이저. 단순히 p.data -= lr * p.grad(경사 하강법)를 할 수도 있지만, Adam은 더 똑똑합니다. 파라미터당 두 가지 이동 평균을 유지합니다: m은 최근 그래디언트의 평균을 추적하고(모멘텀, 굴러가는 공처럼), v는 최근 그래디언트 제곱의 평균을 추적합니다(파라미터별 학습률 조정). m_hat과 v_hat은 m과 v가 0으로 초기화되어 워밍업이 필요한 것을 보정하는 바이어스 보정입니다. 학습률은 학습 전체에 걸쳐 선형으로 감소합니다.
1,000 스텝 동안 손실은 약 3.3(27개 토큰 중 무작위 추측: \(-\log(1/27) \approx 3.3\))에서 약 2.37로 감소합니다. 낮을수록 좋고 가능한 최저값은 0(완벽한 예측)이므로 개선 여지가 있지만, 모델이 이름의 통계적 패턴을 분명히 학습하고 있습니다.
추론
학습이 끝나면 모델에서 새로운 이름을 샘플링할 수 있습니다. 파라미터는 고정되고 순전파만 루프에서 실행하며, 생성된 각 토큰을 다음 입력으로 다시 넣습니다:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
temperature = 0.5 # (0, 1] 범위, 생성 텍스트의 "창의성" 조절, 낮은 값에서 높은 값으로
print("\n--- inference (new, hallucinated names) ---")
for sample_idx in range(20):
keys, values = [[] for _ in range(n_layer)], [[] for _ in range(n_layer)]
token_id = BOS
sample = []
for pos_id in range(block_size):
logits = gpt(token_id, pos_id, keys, values)
probs = softmax([l / temperature for l in logits])
token_id = random.choices(range(vocab_size), weights=[p.data for p in probs])[0]
if token_id == BOS:
break
sample.append(uchars[token_id])
print(f"sample {sample_idx+1:2d}: {''.join(sample)}")
각 샘플을 BOS 토큰으로 시작하여 모델에게 “새 이름을 시작하라”고 알립니다. 모델이 27개의 로짓을 생성하면 확률로 변환하고, 그 확률에 따라 하나의 토큰을 무작위로 샘플링합니다. 그 토큰이 다음 입력으로 다시 들어가고, 모델이 다시 BOS를 생성하거나(“끝났다”) 최대 시퀀스 길이에 도달할 때까지 반복합니다.
temperature 파라미터는 무작위성을 제어합니다. softmax 전에 로짓을 온도로 나눕니다. 온도 1.0은 모델의 학습된 분포에서 직접 샘플링합니다. 낮은 온도(여기서는 0.5)는 분포를 날카롭게 만들어 모델이 상위 선택지를 선호하게 합니다. 0에 가까운 온도는 항상 가장 가능성 높은 토큰을 선택합니다(그리디 디코딩). 높은 온도는 분포를 평평하게 하여 더 다양하지만 덜 일관된 출력을 생성합니다.
실행하기
Python만 있으면 됩니다(pip install 없음, 의존성 없음):
1
python train.py
스크립트는 맥북에서 약 1분 정도 걸립니다. 각 스텝마다 손실이 출력됩니다:
1
2
3
4
5
6
7
8
train.py
num docs: 32033
vocab size: 27
num params: 4192
step 1 / 1000 | loss 3.3660
step 2 / 1000 | loss 3.4243
step 3 / 1000 | loss 3.1778
...
~3.3(무작위)에서 ~2.37로 내려가는 것을 지켜보세요. 학습이 끝나면 학습 토큰 시퀀스의 통계적 패턴에 대한 지식이 모델 파라미터에 증류됩니다.
단계별 진행
코드가 양파의 층처럼 하나씩 쌓이는 것을 보려면, 권장하는 진행 순서는 다음과 같습니다:
| 파일 | 추가하는 것 |
|---|---|
train0.py | 바이그램 카운트 테이블 — 신경망 없음, 그래디언트 없음 |
train1.py | MLP + 수동 그래디언트(수치적 & 해석적) + SGD |
train2.py | 자동 미분(Value 클래스) — 수동 그래디언트 대체 |
train3.py | 위치 임베딩 + 단일 헤드 어텐션 + rmsnorm + 잔차 |
train4.py | 멀티-헤드 어텐션 + 레이어 루프 — 전체 GPT 아키텍처 |
train5.py | Adam 옵티마이저 — 이것이 train.py |
build_microgpt.py라는 Gist를 만들었는데, Revisions에서 이 모든 버전과 각 단계 간의 diff를 볼 수 있습니다.
실제 프로덕션과의 차이
microgpt는 GPT를 학습하고 실행하는 완전한 알고리즘적 본질을 담고 있습니다. 하지만 이것과 ChatGPT 같은 프로덕션 LLM 사이에는 변경되는 것들의 긴 목록이 있습니다. 핵심 알고리즘과 전체 구조를 바꾸는 것은 없지만, 대규모에서 실제로 작동하게 만드는 것들입니다:
데이터. 32K개의 짧은 이름 대신, 프로덕션 모델은 수조 토큰의 인터넷 텍스트로 학습합니다. 데이터는 중복 제거되고, 품질 필터링되며, 도메인 간 신중하게 혼합됩니다.
토크나이저. 단일 문자 대신, 프로덕션 모델은 BPE(Byte Pair Encoding) 같은 서브워드 토크나이저를 사용합니다. ~100K 토큰의 어휘를 제공하며 위치당 더 많은 내용을 볼 수 있어 훨씬 효율적입니다.
자동 미분. microgpt는 순수 Python의 스칼라 Value 객체에서 작동합니다. 프로덕션 시스템은 텐서를 사용하고 GPU/TPU에서 실행됩니다. 수학은 동일하고, 많은 스칼라가 병렬로 처리되는 것에 해당합니다.
아키텍처. microgpt는 4,192개의 파라미터입니다. GPT-4급 모델은 수천억 개입니다. 전반적으로 매우 비슷한 트랜스포머 신경망이며, 훨씬 넓고(임베딩 차원 10,000+) 깊습니다(100+ 레이어). 현대 LLM은 RoPE, GQA, 게이트 선형 활성화, MoE 레이어 등 몇 가지 더 많은 레고 블록을 통합합니다. 하지만 잔차 스트림 위에 어텐션(통신)과 MLP(계산)가 번갈아 배치되는 핵심 구조는 잘 보존되어 있습니다.
학습. 스텝당 하나의 문서 대신, 프로덕션 학습은 대규모 배치, 그래디언트 누적, 혼합 정밀도, 신중한 하이퍼파라미터 튜닝을 사용합니다. 프론티어 모델 학습에는 수천 대의 GPU가 몇 달간 실행됩니다.
후처리(Post-training). 학습에서 나온 기본 모델(“사전학습” 모델)은 문서 완성기이지 챗봇이 아닙니다. ChatGPT로 만드는 것은 두 단계로 이루어집니다. 첫째, SFT(지도 미세조정): 문서를 큐레이션된 대화로 교체하고 계속 학습합니다. 알고리즘적으로 변하는 것은 없습니다. 둘째, RL(강화 학습): 모델이 응답을 생성하고, 점수가 매겨지며(인간, “심판” 모델, 또는 알고리즘에 의해), 모델이 그 피드백에서 학습합니다.
추론. 수백만 사용자에게 모델을 서빙하려면 자체 엔지니어링 스택이 필요합니다: 요청 배칭, KV 캐시 관리 및 페이징(vLLM 등), 속도를 위한 투기적 디코딩, 메모리를 줄이기 위한 양자화(float16 대신 int8/int4), 여러 GPU에 모델 분산. 근본적으로는 여전히 시퀀스의 다음 토큰을 예측하지만 더 빠르게 만들기 위한 많은 엔지니어링이 들어갑니다.
이 모든 것이 중요한 엔지니어링 및 연구 기여이지만, microgpt를 이해한다면 알고리즘적 본질을 이해한 것입니다.
FAQ
모델이 무언가를 “이해”하나요? 철학적 질문이지만, 메커니즘적으로는: 마법은 일어나지 않습니다. 모델은 입력 토큰을 다음 토큰에 대한 확률 분포로 매핑하는 큰 수학 함수입니다. 이것이 “이해”를 구성하는지는 여러분에게 달려 있지만, 메커니즘은 위의 200줄에 완전히 담겨 있습니다.
왜 작동하나요? 모델은 수천 개의 조절 가능한 파라미터를 가지고 있고, 옵티마이저가 각 스텝마다 조금씩 손실을 줄이도록 밀어줍니다. 많은 스텝에 걸쳐 파라미터는 데이터의 통계적 규칙성을 포착하는 값으로 정착합니다. 모델은 명시적인 규칙을 배우는 것이 아니라, 그것들을 반영하는 확률 분포를 학습합니다.
ChatGPT와 어떤 관련이 있나요? ChatGPT는 이 동일한 핵심 루프(다음 토큰 예측, 샘플링, 반복)가 엄청나게 확장되고, 대화형으로 만들기 위한 후처리가 추가된 것입니다. 대화할 때, 시스템 프롬프트, 여러분의 메시지, 모델의 응답은 모두 시퀀스의 토큰일 뿐입니다.
“환각”이 뭔가요? 모델은 확률 분포에서 샘플링하여 토큰을 생성합니다. 진실이라는 개념이 없고, 학습 데이터를 기반으로 통계적으로 그럴듯한 시퀀스만 압니다. microgpt가 “karia” 같은 이름을 “환각”하는 것은 ChatGPT가 거짓 사실을 자신 있게 말하는 것과 같은 현상입니다.
왜 이렇게 느린가요? microgpt는 순수 Python에서 한 번에 하나의 스칼라를 처리합니다. GPU에서 같은 수학은 수백만 개의 스칼라를 병렬로 처리하여 몇 자릿수 더 빠르게 실행됩니다.
더 좋은 이름을 생성할 수 있나요? 네. 더 오래 학습하거나(num_steps 증가), 모델을 더 크게 만들거나(n_embd, n_layer, n_head), 더 큰 데이터셋을 사용하세요. 이것은 대규모에서도 중요한 동일한 조절 요소입니다.
데이터셋을 바꾸면? 모델은 데이터에 있는 어떤 패턴이든 학습합니다. 도시 이름, 포켓몬 이름, 영어 단어, 또는 짧은 시로 교체하면 모델은 그것들을 생성하는 법을 학습합니다. 나머지 코드는 변경할 필요가 없습니다.